Friends who use HubSpot to manage customers on a daily basis may have encountered a problem: they want to export all contact data for analysis or backup, but the HubSpot API has pagination limits – a single request returns a maximum of 100 data items. If there are more, you have to manually turn the pages, download repeatedly, and then manually merge a dozen or even dozens of pages of data into a single spreadsheet…
If there are thousands of contacts, it will take more than an hour to manually process the pagination, and it is easy to miss data or format it incorrectly.
Today I’d like to share with you an n8n automation workflow. Without writing any code, you can simply click a few times to automatically run all paging requests and finally output the merged and complete contact data.
What problems can this workflow solve?
Simply put, its core function is to “automatically handle HubSpot API pagination, batch fetch all contacts and merge the results”.
Specifically, it can help you achieve:
✅ Automatic pagination: When the HubSpot API returns a “next page” link, automatically trigger the next round of requests until all data is captured;
✅ Limit viewership of protection: Automatically wait 5 seconds after each request to avoid being blocked by HubSpot due to too frequent requests;
✅ Data merging: Aggregate all paged contact data into an array and directly export it as a table (such as CSV/Excel);
✅ Fully automated: no manual intervention required from start to output.
How intuitive is the effect? You can tell by looking at the comparison
Manual operation VS automated workflow
| Scene | Manual operation | n8n Automation Workflow |
| 1000 contacts (10 pages) | Manually request the API 10 times, download 10 files, manually copy and paste to merge, which takes about 40 minutes | Click “Execute”, wait for 50 seconds (10 requests x 5 seconds wait), and directly output the complete data. It takes about 1 minute |
| Data Accuracy | Easy to miss pages and copy wrong lines | Automatically processed by the program, zero human error |
| Reuse | Repeat the operation for each export | Configure once and use directly later |
Configure this workflow in 3 steps without programming
Step 1: Prepare the HubSpot API key
First, obtain the HubSpot API key (with contact read permission):
- Log in to the HubSpot backend, and go to [Settings → Integrations → Private Apps → Create a private app].
- Check “Read” in the “Contacts” permission and generate an API key (it will look like this:
pat-na1-xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx).
Step 2: Import the workflow template
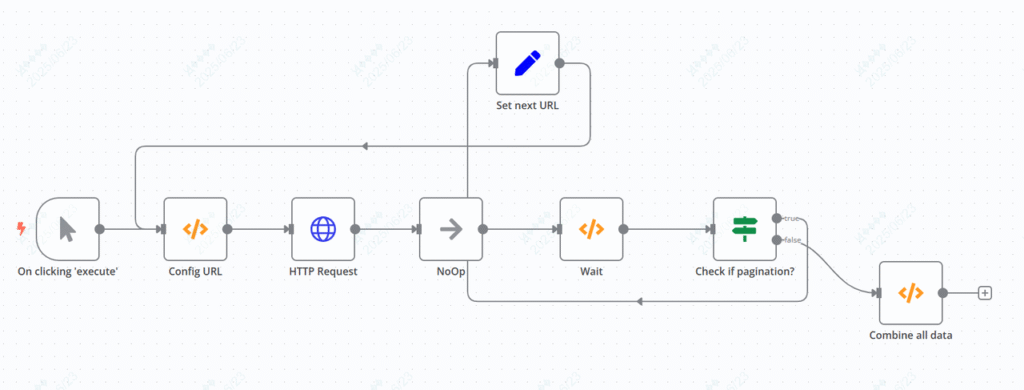
Import the prepared “HubSpot Contact Pagination Crawling” template (the template contains 8 nodes, covering the entire process from triggering to merging) in n8n.
The logic of the core node does not need to be changed. Focus on these two parameters that you need to fill in:
- HTTP Request node: In the “Query Parameters,” replace the value of
hapikeywith the HubSpot API key you just obtained. - Waiting node: Wait for 5 seconds by default (to prevent limit viewership of). If your HubSpot account has a strict limit viewership of, you can change it to 10 seconds (in the code
setTimeout(10000)).
Step 3: Execute the workflow to obtain the merged data
Click the “Execute” button in the upper right corner of n8n, and the workflow will automatically:
- Request the first page of contact data from the HubSpot API (default 100 per page);
- Check if there is a next page (judged by the
pagingfield returned by the API); - If there is a next page, automatically initiate a new request with the “Next Page URL” (loop until all pages are captured);
- Finally, merge the paginated
resultsdata into an array and output a complete contact list (including fields such as name, email, company, and creation time).