Have you ever had this experience: you browse ProductHunt every day to find inspiration for new products. When you see a product that interests you, you want to know what technology they use and how to contact the team. As a result, you have to manually copy the link, open the website, and turn pages to find “Contact Us”. After a series of operations, 10 minutes have passed. Is the efficiency so low that you want to give up?
Recently, I built an automated workflow with n8n to solve this problem: automatically grab new posts from ProductHunt every day, parse out the product website, and directly extract the contact email and technology stack. No manual operation is required throughout the process, and the data is directly summarized
What can this workflow do?
Simply put, it is a ProductHunt new product information mining robot with three core functions:
✅ Automatically monitor new products: Crawl the latest posts on ProductHunt at a fixed time every day (such as 6 am and 6 pm), so you don’t have to manually refresh the website;
✅ Track product website: Extract the hidden product link from the post and automatically jump to the actual product official website
✅ Extract key information: After getting the official website, automatically analyze the contact email and technology stack.
Finally, you will get Structured Data: product title, official website, contact email, technologies used… You can use it directly, saving 80% of the manual operation time.
Implementation Logic: 5-step Automation Process Breakdown
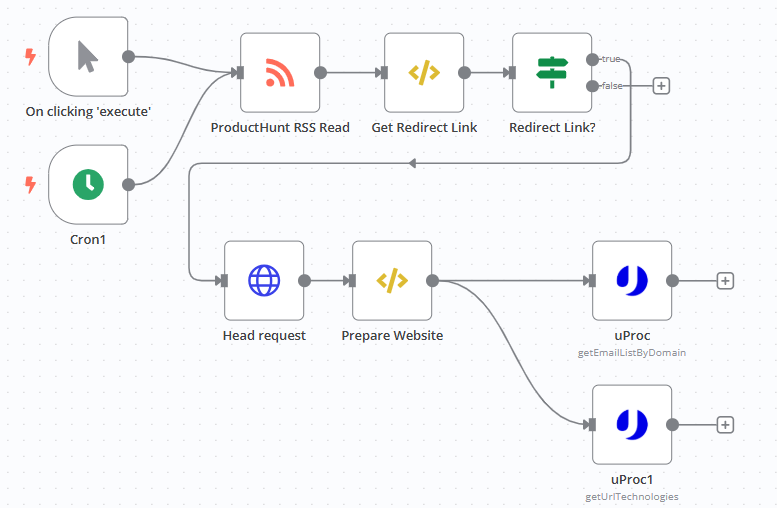
You may think that “automation” sounds complicated, but n8n makes it simple. The core steps of this workflow are actually only five steps:
Step 1: Start the timer
Two triggering methods are used here:
- Timed trigger : Run automatically at 6:00 and 18:00 every day (configured through the Cron node, similar to an alarm clock), covering the peak of new product releases in the morning and evening;
- Manual trigger : Want to check a batch of data temporarily? Just click the “Execute” button, which is suitable for urgent needs.
Regardless of the trigger method, the “Get ProductHunt Data” process will be initiated automatically without you having to sit in front of your computer.
Step 2: Scrape original data source from ProductHunt RSS
ProductHunt has an official RSS feed (`https://www.producthunt.com/feed`), which contains information such as the title, content, and release time of all new posts. In the workflow, use the “RSS Read Node” to directly subscribe to this feed, and you can get the latest post data, which is equivalent to “automatically downloading the new product list”.
Step 3: “Pick” out the key links from the post
After getting the post data, we need to extract two important links from it:
- Retargeting link: The “Visit Product” button in the ProductHunt post usually jumps to a link like https://www.producthunt.com/r/xxx (e.g. r/abc123), which then jumps to the actual product website;
- Original link of the post: https://www.producthunt.com/posts/xxx, which is convenient for subsequent tracing of post details.
How to extract? Use a simple Regular Expression (you can write a function directly in n8n) to match these two link formats from the post content and automatically “dig” them out. For example, use `/(https:\/\/www.producthunt.com\/r\/[^\”]+)/gi` to accurately locate the Retargeting link.
Step 4: Locate the product official website and clean the URL
After getting the retargeting link (r/xxx), the next step is to find the official website it finally jumps to. Here we use the “HTTP HEAD Request” node: send only a lightweight request to obtain the Location field in the response header – this field is the target of the retargeting, that is, the actual official website of the product (such as `https://www.xxx-product.com?ref=producthunt`).
However, the official website may contain a bunch of parameters (e.g., ?ref=xxx), which is messy and affects subsequent analysis. Therefore, I added a step to “clean the URL”: remove the parameters after ? and keep only the clean domain name (e.g., https://www.xxx-product.com) for the next step.
Step 5: Call the tool to extract the email and technology stack
With a clean official website domain, you can use third – party tools to extract information. Here we use two tools from uProc:
- Get the contact email: call the
getEmailListByDomaininterface, enter the official website domain name, and the public email associated with the domain name will be returned (such as contact@xxx.com, support@xxx.com). - Get the technology stack: Call the
getUrlTechnologiesinterface to analyze what technologies the website uses (such as the front-end framework React, the back-end language Node.js, whether Google Analytics or other statistics are used).
This step is equivalent to “letting the tool search every corner of the website for you”, so you don’t have to manually find the “About Us” and “Contact Us” pages.
What are the actual use cases?
This workflow is not a “toy”, but a practical tool that can be implemented, especially suitable for these types of people:
👉 Marketing/Operation: Quickly collect competing product intelligence
Want to know what technologies the hottest products are using? The workflow can automatically aggregate technology stack data, such as “8 out of 10 new products this week used React, and 3 used Tailwind CSS”, helping you quickly judge technology trends.
👉 Sales / Business: Get the contact email directly
When you see a potentially cooperative product, you don’t need to manually check the official website or search for contact information on social media. The workflow directly outputs the email address. You can copy it and send an email, doubling the efficiency of cold start.
👉 Entrepreneurs/Product Managers: Monitor new product dynamics
Automatically receive the “Product Hunt New Product Briefing” every day, including product name, official website, technology stack, and contact information, to help you quickly filter competing products or sources of inspiration worthy of attention.