Today I’d like to share an n8n workflow that searches for tweets with specific keywords on Twitter, deduplicates them against the tweets already stored in Airtable, and automatically adds new tweets to an Airtable table.
1. Overall logic of the workflow
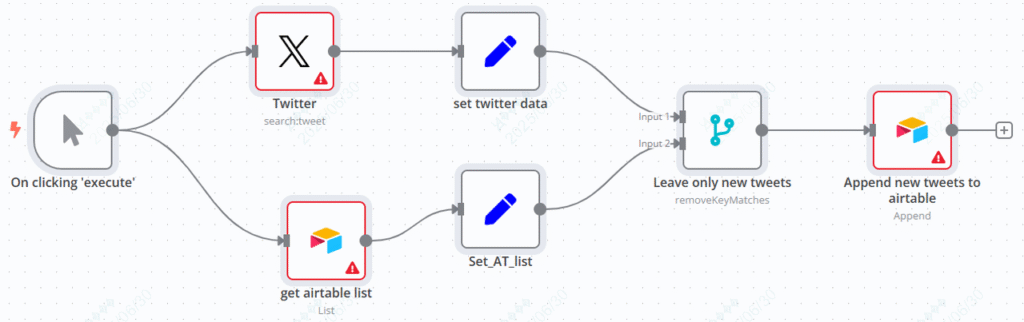
By manually triggering, two parallel branches (“Twitter Search New Tweets” and “Airtable Get History”) are executed simultaneously, and then deduplicated by comparison. Finally, new tweets are stored in Airtable. The process is as follows:
Manual trigger → Search Twitter tweets → Format tweet data → Get Airtable history → Format historical data → Compare and deduplicate (keep new tweets) → Add new tweets to Airtable
2. Analysis of Key Nodes
1. Trigger node: “On clicking ‘execute’”
- Type:
manualTrigger(Manual trigger) - Function: The starting point of the workflow, which triggers the subsequent process by manually clicking the “Execute” button.
- Output: Trigger both branches (“Twitter Search” and “Airtable History Fetch”) simultaneously.
2. Twitter Search Branch
(1) “Twitter” node
- Type:
twitter(Twitter API integration) - Parameter:
operation: "search"(search for tweets);searchText: "verstappen"(search keyword, here “verstappen”, may refer to F1 driver Max Verstappen);limit: 100(return up to 100 tweets);resultType: "mixed"(The result type is mixed, including the latest and popular tweets).
- Function: Search for tweets containing the keyword “verstappen” on Twitter and obtain the original data source (such as tweet text, ID, number of likes, author, etc.).
(2) “set twitter data” node
- Type:
set(data formatting) - Function: Extract and format the fields to be stored from the original data source returned by Twitter, and output Structured Data.
- Key fields (only keep the following fields):
Likes: Number of likes on the tweet (favorite_count);Tweet: Tweet text (text);Tweet_id: Unique tweet ID (id, used to deduplicate);
Tweet URL: Tweet link (constructed as https://twitter.com/[author screen_name]/status/[id_str]Author: The user being replied to (if the tweet is a reply, takein_reply_to_screen_name; may benullif not a reply)Time: Tweet creation time (created_at).
3. Airtable History Branch
(1) “get airtable list” node
- Type:
airtable(Airtable API integration) - Parameter:
operation: "list"(get table records);applicationandtable: Specify the application ID and table ID (target storage table) of Airtable;credentials: Airtable API credentials (used for permission verification).
- Function: Get all stored tweet records (historical data) from the Airtable target table.
(2) “Set_AT_list” node
- Type:
set(data formatting) - Function: Extract the same field structure as the new Twitter tweet from the Airtable history to ensure the same format for subsequent comparison.
- Key fields (only keep the following fields, aligned with the output of “set twitter data”):
Likes,Tweet,Tweet_id,Tweet URL,Author,Time(from thefieldsfield of the Airtable record).
4. Deduplicate node: “Leave only new tweets”
- Type:
merge(data merge/deduplicate) - Mode :
removeKeyMatches(remove records with matching keys) - Parameters:
propertyName1: "Tweet_id",propertyName2: "Tweet_id"(compared byTweet_idfield). - Input :
- Input 0: “set twitter data” outputs new Twitter tweet data;
- Input 1: Airtable historical tweet data output from “Set_AT_list”.
- Function: Compare two Input Streams, <b>remove Tweets from the new Twitter feed whose </b>
<b>Tweet_id</b><b> already exists in the Airtable history</b>, leaving only “new Tweets” that are not in Airtable.
5. Storage Node: “Append new tweets to Airtable”
- Type:
airtable(Airtable API integration) - Parameter:
operation: "append"(add a new record);addAllFields: true(Add all fields of the input data as record fields to the table).
- Function: Add the deduplicated “new tweets” records to the Airtable target table to complete data storage.
3. Workflow Use Cases
- Track and collect tweets on specific topics: Continuously track relevant discussions on Twitter through keywords (e.g., “verstappen”) and automatically collect new tweets into Airtable, avoiding manual copy and paste.
- Deduplicate to avoid duplicate storage : Deduplicate by
Tweet_idunique identifier to ensure that only the first tweet appears in the Airtable table to avoid data redundancy. - Centralized data management: As a lightweight database, Airtable can facilitate subsequent screening, sorting, and analysis of tweet data (such as counting like trends and author distribution), or link with other tools (such as Excel and BI tools).
- Manual trigger flexibility : Support manual execution on demand (not scheduled automatic operation), suitable for scenarios where the collection frequency needs to be flexibly controlled (such as temporarily tracking real-time discussions of an event).
Template download: